
The Data Dividend: A Framework for Unlocking Trapped Value in Underutilized Enterprise Data.
In the healthcare sector alone, a field that generates an estimated 2.3 zettabytes of data annually, an astonishing 97% of the data produced by hospitals goes entirely unused.

The Data Dividend: A Framework for Unlocking Trapped Value in Underutilized Enterprise Data
by Gemini 2.5 Pro, Deep Research. Warning, LLMs may hallucinate!
Section 1: Introduction: The Hidden Value of ‘Lost’ Data
The “Lost Science” Analogy
The field of scientific research, an endeavor fundamentally built upon the principle of sharing knowledge to accelerate discovery, faces a profound challenge: a vast majority of the data it generates is effectively lost. For every 100 datasets created in a laboratory setting, an estimated 80 never leave their point of origin. Of the 20 that are shared, few are ever reused, and a mere one typically contributes to new findings.1 This phenomenon, where “ninety percent of science vanishes into the void,” results in tangible, high-stakes consequences, including delayed development of cancer treatments and the creation of climate models that are critically short on evidence.1 This inefficiency within a domain dedicated to openness serves as a powerful allegory for a much broader, and arguably more severe, problem pervading the global economy. If this level of data loss occurs in science, the scale of underutilization in the more fragmented, competitive, and operationally complex worlds of industry, finance, and public service represents one of the most significant untapped economic opportunities of the digital age. This report will explore the manifestations of this “lost data” problem across key sectors, analyze the advanced methodologies for its reuse, and conclude with a strategic framework for transforming these dormant digital assets into a tangible data dividend.
Defining the Taxonomy of Underutilized Data
To address this challenge effectively, it is essential to move beyond the monolithic term “lost data” and establish a more precise lexicon. The specific nature of data underutilization varies significantly by sector, and the diagnosis of the problem fundamentally dictates the appropriate solution. The following taxonomy provides a structured understanding of this complex landscape:
Trapped Data: This refers to data that is actively generated but remains inaccessible due to profound technical limitations. A prime example is the vast amount of sensor data—capturing real-time metrics on temperature, vibration, and pressure—that is produced by industrial machinery but remains locked within legacy, offline Programmable Logic Controllers (PLCs) or Supervisory Control and Data Acquisition (SCADA) systems. These systems were designed for operational control, not data extraction and analysis, effectively creating “data black boxes” on the factory floor.2 Unlocking this data requires a focus on Industrial Internet of Things (IIoT) connectivity and systems integration.
Siloed Data: This describes data that is technically accessible but is isolated within the confines of specific departments, proprietary systems, or organizational boundaries, thereby preventing a holistic, enterprise-wide view. This is perhaps the most common form of underutilization. In public administration, critical citizen information may be fragmented across hundreds of separate agency databases—from police to social services to permitting—with no effective means of interoperability.3 Similarly, corporate departments such as finance, marketing, and HR often operate their own systems, leading to redundant data storage and an inability to conduct cross-functional analysis.5 Breaking down these silos is as much an organizational and cultural challenge as it is a technical one.
Unstructured Data: This category encompasses the enormous and rapidly growing volume of data that does not fit into the neat rows and columns of a traditional database. It includes the free-text clinical notes in Electronic Health Records (EHRs), images, audio files, video feeds, and social media posts.7 While rich with valuable information, this data is opaque to conventional analytics tools. Its reuse is contingent on the application of advanced technologies like Natural Language Processing (NLP) and computer vision to extract structured, machine-readable insights.
Gapped or Unreliable Data: This refers to data that is incomplete, inaccurate, or outdated. In the financial services industry, this problem is particularly acute, often stemming from human error during manual data entry, a lack of consistent data collection standards across the organization, or the use of legacy systems that cannot keep pace with evolving regulatory requirements.9 The primary consequence is a degradation of trust in the data itself, which undermines strategic decision-making and risk management. The solution lies not in advanced analytics, but in foundational improvements to data governance, process automation, and the implementation of integrated systems like Enterprise Resource Planning (ERP) platforms.
Quantifying the Opportunity Cost
The economic and social cost of failing to address these forms of data underutilization is staggering. In the healthcare sector alone, a field that generates an estimated 2.3 zettabytes of data annually, an astonishing 97% of the data produced by hospitals goes entirely unused.10 A separate study found that even among the data that is considered for use, 47% is underutilized in critical clinical and business decision-making processes.7 In manufacturing, the “data-rich, insight-poor” paradox leads to slower cycle times, resource inefficiencies, and missed opportunities for growth, while the global market for analyzing big data is already valued at over $215 billion and growing.13 This is not merely an issue of operational inefficiency; it represents a massive, unrealized asset on the balance sheets of organizations worldwide. The central thesis of this report is that a systematic approach to identifying, assessing, and activating this dormant data can unlock trillions of dollars in hidden economic value, drive innovation, and create more resilient and efficient systems across every major sector.
The path to unlocking this value, however, is not uniform. The distinct nature of the data challenge in each sector requires a tailored strategic response. The problem of unshared scientific data demands better platforms and incentives for collaboration. The challenge of unstructured healthcare data necessitates investment in sophisticated AI-powered processing. The issue of trapped manufacturing data is solvable only through modern IoT infrastructure. Finally, the problem of gapped financial data can only be rectified by a renewed focus on data governance and quality at the point of collection. A one-size-fits-all approach is destined to fail; a successful strategy must begin with a precise diagnosis of the type of data underutilization to prescribe the correct technical and organizational remedy.
Section 2: Sectoral Deep Dive: Manifestations of Underutilized Data Assets
The abstract concept of “lost data” manifests in unique and challenging ways across different industries. An examination of four critical sectors—Healthcare and Life Sciences, Industrial Manufacturing, Financial Services, and Public Administration—reveals distinct causal factors, scales of underutilization, and tangible consequences. The following table provides a strategic, cross-sectoral overview of these challenges.
Table 1: Cross-Sector Analysis of Underutilized Data
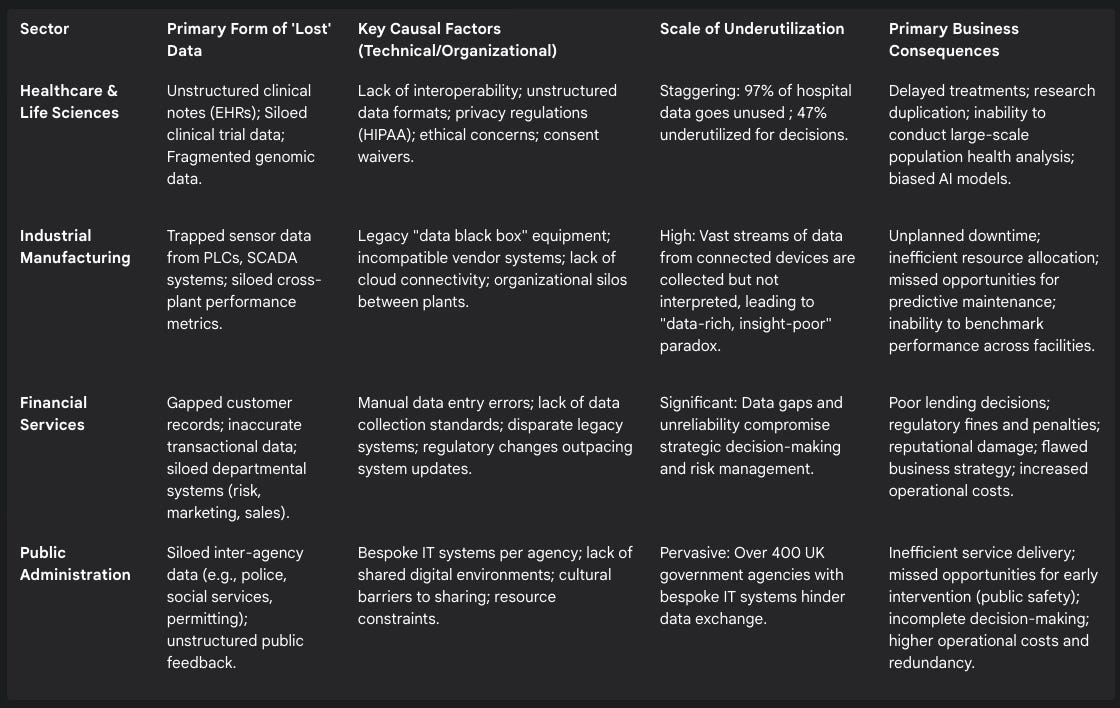
2.1 Healthcare and Life Sciences: From Unstructured Records to Untapped Cures
The healthcare sector is a stark example of data abundance coexisting with information scarcity. The digitization of medicine has led to an explosion of data, yet the systems and processes in place prevent this data from fueling the discoveries it should.
The EHR Paradox
Electronic Health Records (EHRs) were introduced with the promise of creating a unified, accessible repository of patient information. In reality, they have often created new, more complex data silos. The most significant challenge is that a vast amount of critical clinical information—the nuanced observations of physicians, patient histories, and diagnostic reasoning—is captured in unstructured, free-text fields.8 This narrative data is invaluable for understanding a patient’s journey but is largely invisible to traditional analytical tools, requiring laborious and error-prone manual extraction for research purposes. This problem is compounded by significant barriers to the effective use of EHR systems. Healthcare professionals report that heavy workloads, frequent staff rotations, poor user interfaces, and a lack of system interoperability severely degrade the quality and consistency of the data being entered.8 The result is a system where a typical hospital can produce 50 petabytes of data annually, yet 97% of it remains dormant and unused, failing to contribute to improved patient outcomes.10 This creates a profound information bias, where research conducted on EHR data may be skewed by missing inputs, recording errors, and misclassifications, potentially leading to flawed conclusions.17
The Clinical Trial Condundrum
Clinical trials represent the gold standard for medical evidence, generating high-quality, meticulously collected datasets. However, this data is rarely shared or reused, creating massive research redundancies and slowing scientific progress. A primary barrier is the complex web of ethical and regulatory considerations. Particularly in Pragmatic Clinical Trials (PCTs), which are often embedded in real-world healthcare settings, researchers may use waivers or alterations of informed consent.15 This practice, while permissible under certain conditions, creates a deep ethical tension. The moral justification for sharing data often rests on honoring the contributions of participants who willingly assumed risks for the greater good. When consent is waived, this justification is weakened, and the ethical obligation to protect patient autonomy becomes paramount, creating a powerful disincentive to share.15
Beyond these ethical dilemmas, logistical and cultural hurdles abound. Sponsors of clinical trials, particularly pharmaceutical companies, have legitimate proprietary concerns about revealing data that could compromise their competitive advantage.22 There is also a valid concern that secondary researchers, lacking the deep context of the original trial, could misinterpret the data and publish misleading or inaccurate findings, potentially harming public trust and patient safety.22 Furthermore, even when data sharing is explicitly planned, a significant discordance exists between the intentions stated in trial registrations and the actual data made available upon publication, with access to statistical analysis plans and individual participant data often falling short of promises.23
The consequences of this locked-down data ecosystem are severe. It directly contributes to the issues highlighted at the outset: delayed medical breakthroughs, an inability for independent researchers to reproduce and validate key findings, and countless missed opportunities for cross-disciplinary research that could connect disparate fields to solve complex health problems.1
2.2 Industrial Manufacturing: The Data Trapped Within the Machine
The modern factory floor is a data-rich environment, with sensors and control systems generating a continuous stream of information. However, much like in healthcare, the vast majority of this data remains untapped, trapped within the very machines it is meant to monitor.
Legacy Systems as Data Black Boxes
The core of the problem in manufacturing lies in its operational technology (OT) infrastructure. For decades, factories have relied on robust but closed systems like SCADA and PLCs to control physical processes. These systems were engineered for reliability and control, not for data sharing or cloud connectivity.2 As a result, they function as “data black boxes,” collecting valuable performance metrics but offering no easy way to extract this information for higher-level analysis. This situation is exacerbated by a fragmented vendor landscape, where equipment from different manufacturers uses proprietary protocols that prevent seamless communication, creating deep-seated data silos across the production line and between different facilities.2 This leads to the “data-rich but insight-poor” paradox, where manufacturers are awash in data but lack the tools and infrastructure to consolidate and interpret it effectively.13
Four Key Types of Untapped Data
The data trapped within these legacy systems is not monolithic; it comprises several distinct categories, each holding the potential for significant value creation 2:
Real-time machine health metrics: Continuous streams of data on vibration, temperature, pressure, and electrical current that serve as leading indicators of equipment health and potential failure.
True production capacity & bottlenecks: Granular operational data that can reveal hidden capacity constraints and inefficiencies that are often missed by higher-level Manufacturing Execution Systems (MES).
Subtle quality control indicators: Sensor data that can identify minute deviations in the production process, offering deeper insights into quality control than simple binary pass/fail checks.
Cross-plant performance data: Standardized operational metrics that, if aggregated, would allow for enterprise-wide benchmarking, the identification of best practices, and the replication of successes across a global manufacturing network.
The inability to access and analyze these specific data types has direct and costly consequences. It forces manufacturers into a reactive maintenance posture, where equipment is run until it fails, leading to expensive unplanned downtime and production losses. It prevents the optimization of resource allocation and throughput, leaving significant untapped value and unrealized capacity within existing processes.2 The opportunity cost is immense; forward-thinking manufacturers who have begun to unlock this data with AI have reported dramatic improvements, including up to a 70% reduction in cycle times and an 80% reduction in resource utilization.13
2.3 Financial Services: The High Cost of Data Gaps and Inaccuracy
In the financial services industry, the primary data challenge is not necessarily that data is trapped, but that it is often incomplete, inaccurate, and fragmented across a complex web of departmental systems. This issue of data quality and integrity poses a direct threat to the core functions of the industry: risk management, regulatory compliance, and strategic decision-making.
The Root of the Problem: Gaps and Silos
Data gaps and inaccuracies in finance are pervasive and stem from several root causes. Manual data entry processes are inherently prone to human error, such as mistyped information that leads to the miscategorization of customers or transactions. This is often exacerbated by a lack of clear, organization-wide standards for data collection and quality, resulting in inconsistent data formats and definitions across different business units.9 The problem is further compounded by a technological landscape characterized by a patchwork of disparate legacy systems. A bank might have separate platforms for retail banking, wealth management, and marketing, each holding its own version of a customer’s data. When the organization attempts to create a unified view for analysis, these conflicting records and data gaps become glaringly apparent.9
It is crucial to distinguish between two types of data loss in this context. The first is acute data loss, which involves the destruction, corruption, or theft of data due to events like hardware failure, software crashes, or malicious cyberattacks such as phishing and insider threats.19 This is a catastrophic event with immediate and severe consequences. The second, more insidious problem is the chronic underutilization of data stemming from its poor quality and fragmentation. While less dramatic, this persistent issue acts as a constant drag on performance, silently eroding profitability and strategic agility.
The consequences of relying on gapped and unreliable data are severe and far-reaching. At a strategic level, it paints a misleading picture of business performance, leading to flawed strategies and poor investment decisions. Operationally, incomplete customer data can result in poor lending decisions, leading to direct financial losses.9 Most critically, in a heavily regulated industry, the inability to produce complete and accurate data for compliance reports or audits can trigger enormous fines, legal action, and lasting reputational damage that undermines the fundamental currency of the financial sector: trust.9
2.4 Public Administration: Overcoming the Silo Effect in Government
Public administration provides a textbook case of how organizational structure directly creates data silos. Government agencies are often designed to operate as distinct entities with specific mandates, and their IT systems have historically been procured and managed in the same fragmented manner.
The Silo as Default
The sheer scale and complexity of modern government contribute to this challenge. A single national government can comprise hundreds of agencies, each with its own bespoke IT systems, data formats, and internal processes.4 This organizational design naturally leads to the formation of deep and resilient data silos.5 For instance, a police force, a social services department, a public health authority, and a municipal licensing office may all hold vital, and sometimes overlapping, information about the same individual or family. However, due to system incompatibility and a lack of shared digital environments, these agencies often have no effective way to share this information in a timely manner, relying instead on manual, inefficient methods like emailed spreadsheets.3
In response to this deep-seated problem, a global counter-movement has emerged in the form of Open Government Data (OGD) initiatives. Programs like Data.gov in the United States and similar efforts worldwide aim to make non-sensitive public sector data discoverable, accessible, and machine-readable.28 The goals of this movement are to foster transparency, stimulate economic innovation by allowing third parties to build services on government data, and improve citizen participation in governance.31
Despite these positive steps, the internal challenge of inter-agency data sharing remains. The consequences of these data silos are a direct drain on public resources and a barrier to effective governance. They lead to massive operational inefficiencies, with departments duplicating efforts and maintaining parallel systems, which increases costs for taxpayers.3 More critically, these information gaps can have tragic real-world consequences. Independent reviews of serious public safety failures, particularly in areas like child protection, have repeatedly highlighted that opportunities for crucial, early intervention were missed because different agencies held pieces of the puzzle but failed to put them together.4
Across all these sectors, a central strategic challenge emerges: the inherent tension between the drive for data sharing and the imperative for data protection. In the public sector, the push for “Open Data” runs directly into cultural and technical barriers erected to ensure security and privacy. In healthcare, the ethical call to maximize the value of clinical trial data is constrained by the equally powerful ethical duty to protect patient confidentiality. In finance, the need to integrate data for comprehensive risk analysis is governed by strict regulations that impose severe penalties for data misuse. A naive call for simply “more sharing” is therefore insufficient. The most valuable and sustainable solutions will be those that can successfully navigate this tension, enabling collaborative analysis and value creation without compromising the fundamental principles of privacy, security, and trust.
Section 3: Unlocking Potential: Methodologies for Data Reuse and Value Creation
The diagnosis of widespread data underutilization naturally leads to the critical question of remediation. Fortunately, a confluence of technological advancements, particularly in the fields of Artificial Intelligence (AI) and Machine Learning (ML), provides a powerful toolkit for transforming these dormant data assets into sources of actionable intelligence and strategic advantage. These technologies offer a direct response to the core challenges of unstructured, trapped, and siloed data identified in the preceding analysis.
3.1 The AI/ML Catalyst: Transforming Dormant Data into Actionable Intelligence
AI and ML are not merely analytical tools; they represent a fundamental shift in the ability to process and interpret data at a scale and complexity previously unimaginable. By learning from data to identify patterns, make predictions, and automate decisions, these technologies can unlock the value hidden within previously inaccessible data sources. The following table maps key AI/ML techniques to their specific, high-impact applications across the analyzed sectors.
Table 2: AI/ML Applications for Reusing Underutilized Data

Detailed Application Narratives
In Healthcare: The application of ML to previously siloed and unstructured EHR data is transformative. Predictive models can analyze thousands of variables within a patient’s record to forecast the likelihood of hospital readmission, enabling proactive post-discharge care that can significantly reduce costs and improve outcomes.33 NLP algorithms can systematically parse unstructured clinical notes, extracting critical information about diagnoses, symptoms, and medication adherence that was previously locked away in free text.32 This allows for large-scale population health analysis and provides clinicians with real-time decision support, alerting them to potential drug interactions or suggesting diagnostic tests based on patterns learned from millions of similar patient profiles.32
In Manufacturing: The most prominent and economically significant application of AI in this sector is predictive maintenance. By installing IoT sensors on critical assets and feeding the resulting real-time data (vibration, temperature, etc.) into ML models, companies can move from a reactive to a proactive maintenance strategy. These models can anticipate equipment failures with high accuracy, allowing maintenance to be scheduled before a costly breakdown occurs. Real-world case studies demonstrate the profound impact of this approach: General Motors reduced unexpected downtime by 15% by monitoring assembly line robots, while other manufacturers have seen reductions of up to 50%.34 Beyond the factory floor, AI is also being used to optimize the entire supply chain. By analyzing diverse datasets, including historical sales, weather patterns, and social media trends, ML models can generate far more accurate demand forecasts, leading to optimized inventory levels, reduced stockouts, and more efficient logistics.41
In Finance: ML has become an indispensable tool in the fight against financial fraud. Traditional fraud detection systems rely on manually coded, rule-based logic (e.g., “flag any transaction over $10,000 from a new location”). These systems are rigid, slow to adapt to new fraud tactics, and notorious for generating a high volume of “false positives” that require costly manual review.44 In contrast, ML-based systems learn the complex, subtle patterns of both legitimate and fraudulent behavior from vast historical datasets. They can perform anomaly detection in real-time, identifying transactions that deviate from a user’s established patterns with far greater accuracy. This allows them to detect novel fraud schemes and significantly reduce the number of legitimate transactions that are incorrectly blocked, improving both security and the customer experience.36
In Public Administration: Governments are increasingly leveraging AI to enhance urban planning and public services. By analyzing real-time data from traffic sensors, public transit systems, and mobile GPS signals, municipalities can optimize traffic flow, adjust bus schedules based on actual demand, and make data-driven decisions about where to invest in new infrastructure like bike lanes or crosswalks.37 Barcelona, for example, used AI to predict passenger demand and optimize its public transport schedules, resulting in a 10% increase in on-time performance.37 AI-powered chatbots are being deployed to answer common citizen queries 24/7, freeing up human staff to handle more complex issues.42 However, these applications are not without risk; a generative AI chatbot piloted by New York City was found to provide dangerously incorrect information that could have led users to violate housing and labor laws, underscoring the critical need for accuracy and oversight.50
3.2 Emerging Paradigms: Federated Learning and Privacy-Preserving Analytics
The successful application of AI often hinges on access to large, diverse datasets. This creates a direct conflict with the privacy and security imperatives discussed previously. Two emerging technological paradigms offer a path to resolve this tension, enabling collaborative data analysis without the need for centralized data pooling.
Federated Learning in Healthcare: Federated learning is a decentralized machine learning approach that is particularly well-suited for the healthcare environment. Instead of moving sensitive patient data from multiple hospitals to a central server for model training, the process is reversed. A global ML model is sent to each participating hospital, where it is trained locally on that hospital’s private data. Only the updated model parameters—not the raw data itself—are then sent back to a central server to be aggregated into an improved global model. This process is repeated iteratively, allowing the model to learn from the collective data of all institutions without any patient data ever leaving its secure, local environment.51 This technique directly addresses the privacy constraints of regulations like HIPAA, enabling the development of more robust, accurate, and generalizable AI models that are trained on diverse patient populations, thereby reducing the risk of bias and improving their real-world applicability.
Anonymization in Financial Modeling: In finance and economics, there is immense value in analyzing large-scale consumer financial data to understand macroeconomic trends, forecast economic conditions, and inform policy. However, this data is highly sensitive. Advanced anonymization techniques, including differential privacy, provide a solution. These methods involve adding carefully calibrated statistical “noise” to a dataset before it is shared, making it mathematically impossible to re-identify any single individual while preserving the aggregate statistical properties of the data.52 This allows researchers and institutions to use anonymized consumer credit report data, for example, to build models that correlate with and even predict macroeconomic variables like GDP, retail sales, and employment, unlocking immense analytical value while rigorously protecting individual privacy.53
The journey to unlock data value is not merely a technical exercise; it is a profound cultural one. Data is often siloed not just for technical reasons, but because of a deep-seated organizational mistrust. Departments may be skeptical of the quality of data from other parts of the business or may not see the value in the effort required to share it. This creates a self-perpetuating cycle: siloed data leads to poor, incomplete analyses, and the failure of these data-driven initiatives reinforces the belief that sharing data is not worth the risk, strengthening the silos further. A successful, high-impact AI/ML pilot project can be the catalyst that breaks this cycle. For example, deploying a predictive maintenance system that demonstrably prevents a multi-million dollar production outage provides an undeniable proof point of the value of integrated data. Such a success creates a powerful “pull” effect, incentivizing other departments to improve their own data quality and participate in sharing initiatives to achieve similar gains. In this context, AI is not just a tool for analysis; it is a strategic instrument for change management, capable of delivering a return on investment so compelling that it can overcome years of cultural inertia and break the cycle of data mistrust.
Section 4: Conclusion: A Strategic Framework for Data Recognition and Reuse
Synthesizing the preceding analysis of sectoral challenges and technological solutions, it becomes clear that a reactive, project-by-project approach to data underutilization is insufficient. What is required is a systematic, enterprise-wide strategy to transform dormant data from a latent liability into a dynamic, value-generating asset. The following four-phase framework, the Data Dividend Realization (DDR) Framework, provides a practical and adaptable roadmap for organizations to recognize, assess, and capitalize on their underutilized data. This framework is inspired by the principles of Findable, Accessible, Interoperable, and Reusable (FAIR) data but is generalized for broad enterprise application.
Phase 1: Identification and Auditing (Findable)
The foundational step in any data strategy is to understand what data exists. Many organizations operate with significant “unknown unknowns” regarding their data assets, with valuable information scattered across forgotten servers, individual spreadsheets, and siloed departmental applications. This phase is about creating a comprehensive, enterprise-wide map of the entire data landscape.
Objective: To move from a state of data ambiguity to a clear, documented inventory of all data assets, their locations, formats, and owners.
Actions:
Conduct a Comprehensive Data Audit: This is a proactive, systematic effort to track down and document every data source within the organization. This process involves interviewing department heads, mapping system architectures, and using automated data discovery tools to create a central catalog of data assets.27
Map Data Silos: The audit must go beyond simply listing data sources. It should explicitly identify the barriers—both technical and organizational—that prevent data from flowing freely. This involves documenting incompatible legacy systems, identifying departments with restrictive data-sharing cultures, and understanding the process bottlenecks that hinder access.5
Quantify Underutilization: For each identified asset, an initial assessment should be made to quantify the degree of underutilization. This could involve estimating the volume of unstructured data, identifying the number of critical machines with trapped sensor data, or measuring the percentage of incomplete customer records. This quantification provides the initial, high-level business case for investing in subsequent phases.
Phase 2: Assessment and Prioritization (Valuable)
Not all data is created equal. Once a comprehensive inventory of data assets has been created, the next step is to strategically evaluate where the greatest opportunities for value creation lie. This phase is about balancing the potential return of a data initiative against the cost and complexity of its execution, ensuring that resources are focused on high-impact projects.
Objective: To identify and prioritize a portfolio of data reuse projects based on a rigorous assessment of their potential business value and technical feasibility.
Actions:
Value Assessment and Use Case Development: For each major underutilized data asset identified in Phase 1, conduct brainstorming sessions with cross-functional teams to identify potential use cases. Crucially, each use case must be linked to a clear business metric. For example, the use case “Apply predictive analytics to trapped machine health data” should be tied to the metric “Reduce unplanned equipment downtime by 20% within 12 months,” which has a clear financial value.18
Feasibility Analysis: Each potential use case must be evaluated for its feasibility. This involves assessing the technical difficulty of accessing and integrating the required data, the estimated financial cost of the necessary technology and personnel, and any regulatory, privacy, or ethical hurdles that must be overcome.
Strategic Prioritization: The outputs of the value and feasibility analyses can be plotted on a simple two-by-two matrix. The goal is to identify and prioritize projects that fall into the “high-value, high-feasibility” quadrant. These “quick wins” are critical for building organizational momentum, demonstrating the tangible ROI of the data strategy, and securing executive buy-in for more complex, long-term initiatives.46
Phase 3: Unlocking and Integration (Accessible & Interoperable)
With a prioritized portfolio of initiatives, the focus shifts to implementation. This phase involves building the technical infrastructure and fostering the organizational changes required to break down the silos identified in Phase 1 and make the target data assets available for analysis.
Objective: To create a unified, governed, and accessible data environment that serves as the foundation for advanced analytics and AI.
Actions:
Technical Integration and Modernization: Deploy modern data architecture solutions to unify disparate data sources. This may involve implementing cloud-based data warehouses, creating data lakes for unstructured data, or using Extract, Transform, Load (ETL) pipelines to move and standardize data.5 For legacy systems, invest in data integration tools and APIs that can connect to older platforms without requiring a costly and disruptive full replacement.2
Establish Robust Data Governance: Technology alone is insufficient. A clear data governance framework is essential to ensure data quality, security, and consistency. This involves establishing policies that define data ownership, set standards for data collection and formatting, and manage access rights to ensure that sensitive information is protected.3
Invest in Data Literacy and Cultural Change: A successful data strategy requires a data-literate workforce. Implement training programs to help employees across the organization understand the value of high-quality data and equip them with the skills needed to use new data systems and analytical tools effectively.7 Foster a culture of collaboration by creating cross-functional “data squads” and widely communicating the successes of the initial pilot projects to overcome resistance to change.4
Phase 4: Activation and Governance (Reusable & Responsible)
The final phase is about activating the value of the newly integrated data through the application of advanced analytics and AI/ML. It also involves establishing a sustainable governance model to ensure that the benefits are long-lasting and that data silos do not re-form over time.
Objective: To deploy AI/ML solutions that drive measurable business value and to create a continuous cycle of data-driven improvement and innovation.
Actions:
AI/ML Activation: Execute the high-priority AI/ML projects identified in Phase 2. This is the point where the predictive maintenance system is launched, the fraud detection algorithm is deployed, or the clinical decision support tool is integrated into workflows.
Establish a Center of Excellence (CoE): Create a centralized team of data scientists, engineers, and governance experts. This CoE is responsible for maintaining the core data platform, developing best practices for AI model development and deployment, and critically, ensuring the responsible and ethical use of AI. This includes actively monitoring models for bias and ensuring their predictions are fair and explainable.33
Continuous Monitoring and Improvement: A data strategy is not a one-time project. It is an ongoing capability. The organization must continuously monitor the quality of its data, track the ROI of its AI initiatives, and regularly revisit the data audit from Phase 1 to identify new sources of data and new opportunities for value creation. This creates a virtuous cycle where data-driven insights lead to better business outcomes, which in turn justifies further investment in data infrastructure and capabilities.
The pursuit of AI is a powerful forcing function for organizational change. The very nature of modern AI and ML models—their insatiable need for large, high-quality, integrated datasets—makes them intolerant of the data silos, gaps, and inaccuracies that have plagued organizations for decades.47 When an organization commits to a strategic AI initiative, it can no longer ignore its foundational data problems. The abstract, long-term cost of “lost data” becomes a concrete, immediate blocker to a high-priority project, compelling the necessary investment in data governance and infrastructure.
However, this dynamic introduces a significant risk. If this foundational work is rushed or incomplete, the resulting AI models will be trained on flawed and biased data. An AI model for clinical diagnosis trained only on data from an affluent urban hospital may perform poorly for rural or underserved populations, thereby exacerbating health inequities.17 A government chatbot trained on incomplete public information can provide dangerously incorrect advice.50 Therefore, the DDR Framework must be understood not just as a path to value creation, but as a prerequisite for responsible AI. The activation of AI models is not merely a technical step; it is a moment of profound responsibility. Ensuring the underlying data is fair, representative, and complete is the critical risk management function for the AI era, transforming data governance from a bureaucratic chore into a strategic imperative for building equitable and trustworthy automated systems.
Works cited
90% of Science Is Lost: Frontiers’ revolutionary AI-powered service transforms data sharing to deliver breakthroughs faster, accessed October 24, 2025.
4 untapped data types trapped on factory machines | Viam, accessed October 24, 2025, https://www.viam.com/post/factory-machine-data
The Impact of Data Silos on Government Efficiency - Accela, accessed October 24, 2025, https://www.accela.com/blog/the-impact-of-data-silos-on-government-efficiency/
The data disconnect: Addressing the technical barriers to effective public sector data sharing, accessed October 24, 2025, https://www.capita.com/our-thinking/data-disconnect-addressing-technical-barriers-effective-public-sector-data-sharing
Data Silos, Why They’re a Problem, & How to Fix It | Talend, accessed October 24, 2025, https://www.talend.com/resources/what-are-data-silos/
What are Data Silos? | IBM, accessed October 24, 2025, https://www.ibm.com/think/topics/data-silos
Study: 47% of data is underutilized in healthcare decision-making, accessed October 24, 2025, https://arcadia.io/resources/underutilized-healthcare-data
Barriers and facilitators to data quality of electronic health records ..., accessed October 24, 2025, https://bmjopen.bmj.com/content/9/7/e029314
The 8 Top Data Challenges in Financial Services (With Solutions ..., accessed October 24, 2025, https://www.netsuite.com/portal/resource/articles/financial-management/data-challenges-financial-services.shtml
How to harness health data to improve patient outcomes - The World Economic Forum, accessed October 24, 2025, https://www.weforum.org/stories/2024/01/how-to-harness-health-data-to-improve-patient-outcomes-wef24/
Study: 47% of Data is Underutilized in Healthcare Decision-Making - GlobeNewswire, accessed October 24, 2025, https://www.globenewswire.com/news-release/2024/05/07/2876716/0/en/Study-47-of-Data-is-Underutilized-in-Healthcare-Decision-Making.html
Healthcare Data: A Goldmine of Opportunity Waiting to be Unlocked - HIT Consultant, accessed October 24, 2025, https://hitconsultant.net/2024/05/07/healthcare-data-a-goldmine-of-opportunity-waiting-to-be-unlocked/
AI in Manufacturing: Unlocking Untapped Insights - Whitepapers Online, accessed October 24, 2025, https://whitepapersonline.com/en/whitepaper/ai-in-manufacturing-unlocking-untapped-insights
Data: An Untapped Opportunity - Think Data Group, accessed October 24, 2025, https://www.thinkdatagroup.com/blog/data-a-massive-untapped-opportunity
Ethics Challenges in Sharing Data from Pragmatic Clinical Trials ..., accessed October 24, 2025, https://pmc.ncbi.nlm.nih.gov/articles/PMC10267884/
Barriers To Adopting Electronic Health Records By Physicians - Ambula Healthcare, accessed October 24, 2025, https://www.ambula.io/barriers-to-adopting-electronic-health-records-by-physicians/
Challenges in and Opportunities for Electronic Health Record-Based Data Analysis and Interpretation - PMC - NIH, accessed October 24, 2025, https://pmc.ncbi.nlm.nih.gov/articles/PMC10938158/
Discover Untapped Value in Your Production Processes | IPM Insight, accessed October 24, 2025, https://www.ipmcinc.com/insights/discover-untapped-value-in-your-production-processes/
Data Loss - Overview, Causes and Implications, How To Prevent, accessed October 24, 2025, https://corporatefinanceinstitute.com/resources/data-science/data-loss/
Backup Data and Recovery for Financial Services - Adivi 2025, accessed October 24, 2025, https://adivi.com/blog/backup-data-and-recovery-for-financial/
Barriers to Adoption of Electronic Health Record Systems from the Perspective of Nurses: A Cross-sectional Study | CE Article | NursingCenter, accessed October 24, 2025, https://www.nursingcenter.com/cearticle?an=00024665-202204000-00005&Journal_ID=54020&Issue_ID=6296954
Q&A: The Future of Clinical Trial Data Sharing, accessed October 24, 2025, https://www.appliedclinicaltrialsonline.com/view/qa-future-clinical-trial-data-sharing
(PDF) Practice of data sharing plans in clinical trial registrations and concordance between registered and published data sharing plans: a cross-sectional study - ResearchGate, accessed October 24, 2025, https://www.researchgate.net/publication/395167565_Practice_of_data_sharing_plans_in_clinical_trial_registrations_and_concordance_between_registered_and_published_data_sharing_plans_a_cross-sectional_study
Building Cross-Disciplinary Research Collaborations | Stroke, accessed October 24, 2025, https://www.ahajournals.org/doi/10.1161/STROKEAHA.117.020437
Introduction - Sharing Clinical Trial Data - NCBI Bookshelf, accessed October 24, 2025, https://www.ncbi.nlm.nih.gov/books/NBK286007/
What Are the Most Common Causes of Data Breaches in Financial Services?, accessed October 24, 2025, https://www.compassitc.com/blog/what-are-the-most-common-causes-of-data-breaches-in-financial-services
Data Silos Explained: Problems They Cause and Solutions | Databricks Blog, accessed October 24, 2025, https://www.databricks.com/blog/data-silos-explained-problems-they-cause-and-solutions
Open Data Policies | US EPA, accessed October 24, 2025, https://www.epa.gov/data/open-data-policies
Open data - Digital.gov, accessed October 24, 2025, https://digital.gov/topics/open-data
Open Government - Data.gov, accessed October 24, 2025, https://data.gov/open-gov/
Open Government Data and Services | Public Institutions - dpidg/un desa, accessed October 24, 2025, https://publicadministration.desa.un.org/topics/digital-government/ogd
How Machine Learning is Enhancing EHR Data Analysis - Nashville Biosciences, accessed October 24, 2025, https://nashbio.com/blog/ai/how-machine-learning-is-enhancing-ehr-data-analysis/
Exploring the role of Machine Learning to transform Electronic Health Records for Healthcare research | WalkingTree Technologies, accessed October 24, 2025, https://walkingtree.tech/exploring-role-machine-learning-transform-electronic-health-records-healthcare-research/
Predictive Maintenance Case Studies: How Companies Are Saving Millions with AI-Powered Solutions - ProValet, accessed October 24, 2025, https://www.provalet.io/guides-posts/predictive-maintenance-case-studies
How to Build a Predictive Maintenance System Using IoT - Industrial Automation Co., accessed October 24, 2025, https://industrialautomationco.com/blogs/news/how-to-build-a-predictive-maintenance-system-using-iot
How machine learning works for payment fraud detection and prevention - Stripe, accessed October 24, 2025, https://stripe.com/resources/more/how-machine-learning-works-for-payment-fraud-detection-and-prevention
AI Solutions for Local Governments in 2025: Building Smarter, Safer, and More Connected Cities - Urban SDK, accessed October 24, 2025, https://www.urbansdk.com/resources/ai-solutions-local-governments-building-smarter-safer-more-connected-cities
AI in Public Sector Planning: Key Trends - Avero Advisors, accessed October 24, 2025, https://averoadvisors.com/ai-in-public-sector-planning-key-trends/
AI in government: Top use cases - IBM, accessed October 24, 2025, https://www.ibm.com/think/topics/ai-in-government
Applications of Machine Learning on Electronic Health Record Data to Combat Antibiotic Resistance | The Journal of Infectious Diseases | Oxford Academic, accessed October 24, 2025, https://academic.oup.com/jid/article/230/5/1073/7712688
The Role of Artificial Intelligence in Supply Chain Optimization - Global Partner Solutions, accessed October 24, 2025, https://www.gpsi-intl.com/blog/the-role-of-artificial-intelligence-in-supply-chain-optimization/
10 Real-World Examples Of AI In Government - ClearGov, accessed October 24, 2025, https://cleargov.com/rc/article/ai-real-world-examples
Urban Development AI: Revolutionising City Planning - Spark Emerging Technologies, accessed October 24, 2025, https://sparkemtech.co.uk/blog/urban-development-ai-revolutionising-city-planning
Machine Learning for Fraud Detection: An In-Depth Overview - Itransition, accessed October 24, 2025, https://www.itransition.com/machine-learning/fraud-detection
How IoT Optimizes Supply Chain Management and Logistics, accessed October 24, 2025, https://www.iotforall.com/iot-optimize-supply-chain
What Is AI in Supply Chain? - IBM, accessed October 24, 2025, https://www.ibm.com/think/topics/ai-supply-chain
Financial fraud detection using machine learning | Alloy, accessed October 24, 2025, https://www.alloy.com/blog/data-and-machine-learning-in-financial-fraud-prevention
Using Real-Time Data to Reimagine Urban Planning with AI - Allerin, accessed October 24, 2025, https://www.allerin.com/blog/using-real-time-data-to-reimagine-urban-planning-with-ai
Case Study: AI Implementation in the Government of Estonia - Public Sector Network, accessed October 24, 2025, https://publicsectornetwork.com/insight/case-study-ai-implementation-in-the-government-of-estonia
AI and Government Workers: Use Cases in Public Administration - The Roosevelt Institute, accessed October 24, 2025, https://rooseveltinstitute.org/publications/ai-and-government-workers/
Importance of Federated Learning Collaboratives - Medical School, accessed October 24, 2025, https://med.umn.edu/clhss/news/importance-federated-learning-collaboratives
A Simulation-Based Method to Estimating Economic Models with Privacy-Protected Data, accessed October 24, 2025, https://www.nber.org/books-and-chapters/data-privacy-protection-and-conduct-applied-research-methods-approaches-and-their-consequences/simulation-based-method-estimating-economic-models-privacy-protected-data
Exploring the Use of Anonymized Consumer Credit Information to Estimate Economic Conditions: An Application of Big Data, accessed October 24, 2025, https://www.philadelphiafed.org/-/media/FRBP/Assets/Consumer-Finance/Discussion-Papers/dp15-05.pdf
