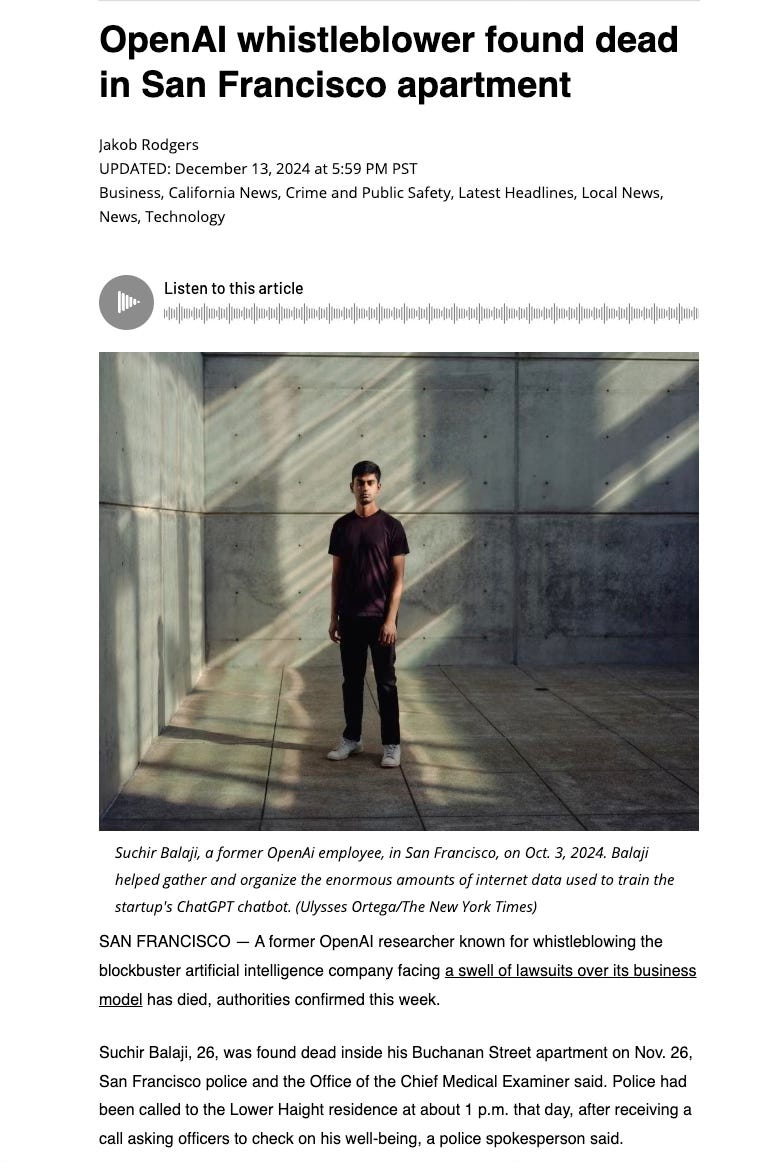
Grok: Suchir Balaji, illustrates the potential for market harm, the commercial nature of AI's use, the copyrighted nature of the training data, and the substantial use of that data in AI outputs
I agree with his perspective. His arguments suggest that the application of fair use to generative AI like ChatGPT is not straightforward and leans towards not qualifying as fair use.


Asking AI services: Please read the following post by Suchar Balaji and tell me whether or not you agree with his views on Fair Use. Start with the quick answer YES or NO and then provide your arguments and evidence.
Claude’s answer:
Yes, I largely agree with Suchir Balaji's analysis of fair use in the context of generative AI, particularly regarding ChatGPT.
Balaji's argument is nuanced and systematically examines the four factors of fair use established in the Copyright Act of 1976. His key points that I find compelling are:
Market Harm (Factor 4): Balaji provides evidence of potential market substitution, such as:
Stack Overflow experiencing a 12% traffic decline after ChatGPT's release
Chegg's stock dropping 40% due to potential competition from AI
The existence of data licensing agreements suggests that training on copyrighted data is not straightforwardly "fair use"
Purpose and Character (Factor 1): He convincingly argues that ChatGPT often serves as a direct substitute for original content sources. His programming example clearly illustrates how AI can provide functionally equivalent answers to those found on platforms like Stack Overflow, potentially reducing traffic and value to the original content creators.
Amount and Substantiality (Factor 3): Balaji's most sophisticated argument uses information theory to demonstrate that generative AI outputs aren't just copies, but contain substantial mutual information with training data. By introducing concepts like relative mutual information (RMI), he shows that AI models extract and repurpose significant creative choices from their training data.
Nature of Copyrighted Work (Factor 2): While he considers this the least important factor, he notes that most internet data is copyrighted to some degree.
Balaji concludes that none of the four fair use factors clearly support ChatGPT's use of training data, a conclusion I find well-reasoned and supported by his detailed analysis.
His analysis is particularly valuable because it goes beyond simplistic "copy or not" definitions and explores the deeper ways generative AI might impact original content creation and distribution.
Grok’s answer:
YES
Arguments and Evidence:
Factor (4): Effect on Market Value:
Suchir Balaji's analysis highlights a significant concern regarding the potential negative market effects of generative AI like ChatGPT on original content providers. He notes the decrease in traffic and engagement on platforms like Stack Overflow and Chegg post-ChatGPT, which could suggest a substitution effect harmful to the market for original copyrighted works. The existence of data licensing agreements with content providers further implies that there is a recognized market value in the data used for training, which could be undermined by unauthorized use. This aligns with a traditional interpretation of factor (4), where such market harms generally weigh against fair use.
Factor (1): Purpose and Character of Use:
Balaji points out that AI models like ChatGPT serve commercial purposes and can produce content that directly substitutes for the original copyrighted works in their training dataset. The discussion on "transformativeness" in his analysis suggests that the outputs of these models might not sufficiently transform the original material to justify fair use. While transformation is key in fair use analysis, the document argues that the primary purpose of many AI outputs is to replicate or provide answers that could otherwise be sought from the copyright holder's material, thus not significantly altering the purpose or character from that of the original.
Factor (2): Nature of the Copyrighted Work:
The document acknowledges that much of the data on the internet, which AI models like ChatGPT use, is indeed copyrighted. Given this, factor (2) tends to weigh against fair use as creative and expressive works are typically given stronger copyright protections. Although this factor might be less influential in some analyses, its presence still supports the argument that the nature of the work used by AI models might not favor fair use claims.
Factor (3): Amount and Substantiality of Use:
Balaji's detailed examination of the information theory metrics like mutual information to assess how much of the copyrighted content is reflected in AI outputs is particularly compelling. The lower entropy of AI-generated text suggests a high degree of reliance on the training data. This analysis indicates that a substantial amount of the original work's informational content is used, even if not verbatim, which could argue against fair use under factor (3). The document's exploration of how reinforcement learning and other techniques might lower output entropy, thereby increasing the likelihood of using copyrighted material, supports this view.
Conclusion: Given the comprehensive analysis by Suchir Balaji, which illustrates the potential for market harm, the commercial nature of AI's use, the copyrighted nature of the training data, and the substantial use of that data in AI outputs, I agree with his perspective. His arguments collectively suggest that the application of fair use to generative AI like ChatGPT is not straightforward and, under current interpretations of the law, leans towards not qualifying as fair use. However, this conclusion must be tempered by the recognition that legal interpretations can evolve, particularly as technology and its societal impacts become better understood.
ChatGPT-4o’s answer:
Quick Answer: YES, I agree with parts of Suchir Balaji's views on Fair Use but believe his analysis overlooks important counterarguments regarding the transformative nature and broader market dynamics of generative AI.
Arguments and Evidence:
Suchir Balaji presents a detailed and thoughtful analysis of Fair Use as applied to generative AI systems like ChatGPT. His points about market harm, the extensive use of copyrighted works during training, and the challenges of applying Fair Use in this context are valid and compelling. However, I believe his conclusions underemphasize certain aspects, particularly the transformative potential of generative AI and the complexities of market impact.
Key Points of Agreement:
Market Impact (Factor 4):
Balaji effectively demonstrates how generative AI models can harm existing markets, such as the decline in Stack Overflow traffic and the financial struggles of Chegg. These examples illustrate that AI-generated outputs can act as substitutes, reducing the demand for original content. This aligns with traditional interpretations of Fair Use, where market harm weighs heavily against the defendant.Substantial Use of Copyrighted Works (Factor 3):
The observation that generative AI models copy entire works during training is accurate. While outputs are rarely verbatim reproductions, the comprehensive use of copyrighted materials in the training process raises legitimate concerns about whether Fair Use should apply.Nature of Copyrighted Works (Factor 2):
Although this factor is typically less significant, Balaji rightly notes that much online content, particularly creative works, is heavily protected under copyright. This further complicates Fair Use defenses for generative AI.
Points of Nuance or Disagreement:
Transformative Use (Factor 1):
Balaji argues that generative AI often acts as a direct substitute for original works, which diminishes its claim to being transformative. While this is true in some cases (e.g., simple question-and-answer substitutions), it overlooks the broader context:Generative AI creates entirely new utilities, such as synthesizing disparate sources into cohesive insights, which adds value distinct from the original works.
Courts have recognized transformative uses in cases where the purpose and character of the use differ significantly from the original, as in Authors Guild v. Google. This reasoning applies to many uses of AI outputs.
Market Harm is Not Universal:
While examples like Stack Overflow and Chegg highlight market harm, they don’t represent all use cases. Generative AI can also create complementary effects, such as expanding access to knowledge or fostering innovation in adjacent industries. Balaji’s analysis does not account for these positive outcomes.Overemphasis on Low-Entropy Outputs:
Balaji associates low-entropy outputs with regurgitation of training data, suggesting that this undermines Fair Use. However, many outputs are novel combinations that demonstrate independent utility. The relationship between entropy and copyright infringement is more complex than his analysis implies.
Conclusion:
While I agree with Balaji's cautious approach to Fair Use in the context of generative AI, I believe his analysis undervalues the transformative potential of AI technologies and overgeneralizes the impact of market harm. A more nuanced interpretation of the Fair Use factors could lead to different conclusions, particularly in cases where AI models create novel, non-competing uses that expand access to information.
Perplexity’s answer:
YES I agree with Suchir Balaji's views on Fair Use as applied to generative AI models like ChatGPT. Balaji presents a comprehensive and well-reasoned analysis that highlights several key points:
Market Effect: Balaji convincingly argues that ChatGPT has a significant negative market effect on websites like Stack Overflow, citing decreased traffic and question posting volumes. This impact on existing markets is a crucial factor in fair use considerations.
Transformative Use: The analysis correctly emphasizes that while ChatGPT may serve similar purposes to some of its training data, it often produces substitutes that compete with the originals. This lack of transformative use weighs against fair use.
Amount and Substantiality: Balaji's innovative information theory approach to quantifying the "amount used" provides a valuable framework for understanding how generative AI models utilize copyrighted material. This method offers a more nuanced view of the third fair use factor.
Commercial Nature: The analysis rightly points out that ChatGPT is a commercial product, which is an important consideration in fair use determinations. While commercial use doesn't automatically preclude fair use, it does weigh against it.
Purpose of Use: Balaji's argument that ChatGPT primarily produces substitutes for its training data is well-supported by examples and analysis. This substitution effect is a key factor in determining whether the use qualifies as fair.
Balaji's analysis provides a thorough and balanced examination of how fair use principles apply to novel AI technologies. It effectively demonstrates that the current application of generative AI models like ChatGPT may not align well with fair use doctrine, particularly given the potential market impacts and the nature of the use.